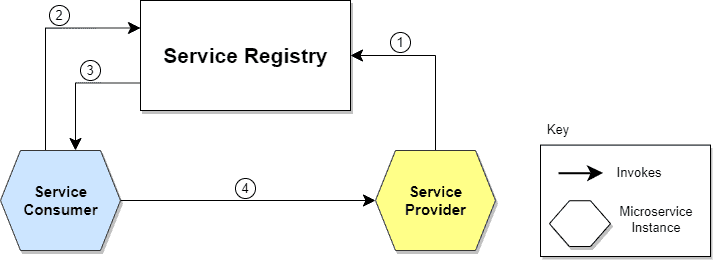
Service Discovery 패턴배경MSA의 분산 환경은 서비스 간 원격 통신으로 동작한다. 아래와 같은 이유로 다른 서비스의 정확한 위치(IP와 포트)를 직접 알고 있지 않고도 서비스 간 통신을 할 필요가 생겼다.cloud 환경에서 가상화/컨테이너화되어 동작하며, 인스턴스의 개수와 위치는 동적으로 변화한다. 또 각 인스턴스는 언제든지 제거/중지될 수도 있다.예를 들어 오토 스케일링에 따라 인스턴스가 계속 바뀌기 때문에 서비스에서 매번 각 인스턴스의 위치와, 어느 인스턴스가 살아있는지를 직접 알고 있을 순 없다.이렇게 언제든 바뀔 수 있는 서비스 위치들을 각 서비스들이 직접 알아야 한다면, 이는 클라우드 환경의 방향성과 도 맞지 않고 유지보수하기 어려운 시스템 구조가 될 것이다. 정의이러한 배경에서 ..
Spring RetryDB, 네트워크 문제, 동시성 등 일시적인 수행 실패로 인해 재수행 처리를 해야 하는 경우가 있다.이 때 try catch문과 반복문을 사용해서 직접 재시도 로직을 구현할 수도 있겠지만, 비즈니스 로직과의 관심사 분리가 어렵게 될 것이다.그런 문제는 AOP로 구현하면 해결되겠지만.. 귀찮을 것이다이러한 재처리 로직을 AOP를 통해 쉽게 적용할 수 있는 Spring 라이브러리가 있다는 것을 최근 업무 중 알게 되었다.Spring Retry 라이브러리는 Spring 어플리케이션에서의 재시도 기능을 제공한다.선언적으로도, 명령형으로도 설정할 수 있다.https://github.com/spring-projects/spring-retry GitHub - spring-projects/sprin..
Spring Event Spring’s eventing mechanism is designed for simple communication between Spring beans within the same application context. However, for more sophisticated enterprise integration needs, the separately maintained Spring Integration project provides complete support for building lightweight, pattern-oriented, event-driven architectures that build upon the well-known Spring programming ..
배경 프로젝트에서 쿼리 개선을 위해 JdbcTemplate를 통해 bulk insert를 구현하게 되었다. 우리는 MySql의 기본키 전략 중 Identity를 사용하고 있어 JPA의 saveAll 메서드로는 bulk insert가 되지 않기 때문이다. 그런데 bulk insert 해야 할 엔티티가 하나가 아니고, 해당 엔티티의 Id를 FK로 가지는 엔티티도 bulk insert해주어야 하는 상황이었다. 따라서 첫 번째 bulk insert의 결과인 Id들을 얻어와야 했고, 그 방법으로 last_insert_id() 함수를 사용할 수 있었다. insert를 한 뒤, Id를 조회해 계산하는 아이디어 자체는 이전에도 생각했다. 하지만 가장 최근 Id를 조회한다면, 의존하는 엔티티의 저장을 마치기 전까지는 테..
현재 진행하고 있는 팀 프로젝트 서비스에서는, 최근에 업데이트된 지도를 메인 화면에 보여주고 있다. 우리 도메인에서 지도에는 사람들이 '핀'을 꽂을 수 있는데, 기존에 관리되는 지도의 '업데이트 일시'는 지도의 생성, 정보 수정 시에만 업데이트되고 있었다. 그래서 오래 전에 만들어진 지도이지만, 방금 핀이 추가되어도 이 지도를 메인 화면에서 빠르게 확인할 수 없었다. 지도 내 핀이 추가되거나, 핀을 수정했을 때에도 지도의 업데이트 일시에 반영될 필요가 있었다. 기존 지도의 updatedAt 외에, 사용자에게 보여줄 정보인 lastPinUpdatedAt 이라는 정보를 추가로 관리하기로 했다. PR 링크로 확인하기 컬럼의 추가 방법으로는 무엇이 있을까? 1. 지도를 조회할 때, 지도가 가진 핀들을 가져와 가..
Youtube 쉬운 코드 채널의 영상을 보고 정리한 내용입니다. https://youtu.be/0PScmeO3Fig?si=mP1V2HZCoZni1sSt Lock의 종류 read-lock (shared lock) read할 때 사용한다. 다른 트랜잭션이 read 하는 것은 허용한다. write-lock (exclusive lock) read/write할 때 사용한다. 다른 트랜잭션이 같은 데이터를 read/write하는 것을 모두 허용하지 않는다. ❗️ write lock이라고 해서, write할 때만 사용되는 것은 아니다! exclusive한 형태라는 점이 중요하다. lock 호환성 같은 데이터에 대해서, 한 트랜잭션이 어떤 lock을 가지고 있을 때, 다른 트랜잭션도 lock을 동시에 가질 수 있을까?..
Youtube 쉬운 코드 채널의 영상을 보고 정리한 내용입니다. https://youtu.be/bLLarZTrebU?si=cQAeGZoEVi9tN5MT SQL 표준 비판 아래와 같은 세 가지 이상 현상과 isolation level은 SQL 표준(standard SQL 92)에서 정의된 내용이다. Dirty read Non-Repeatable read / Fuzzy read Phantom read 격리 수준을 이용해, 위와 같은 이상 현상들이 모두 발생하지 않게 만들 수는 있다. 하지만 그러면 제약 사항이 많아져서 동시에 처리 가능한 트랜잭션 수가 줄어들어 DB의 처리량(throughput)이 하락하는 문제가 생길 수 있다. 그래서, 필요에 따라 일부는 허용할 수 있도록 Isolation 레벨을 나누게 ..
Hikari Connection Pool DataSource 쪽 디버깅을 하다 보면 자주 접했던 이름이지만, 정확히 뭔지는 몰랐다. 2.0 버전부터, Spring Boot의 기본 DataSource로 사용되고 있는 Connection Pool 프레임워크이다. 더 정확히 말하자면, spring-boot-starter-jdbc 또는 spring-boot-starter-data-jpa "starters"를 사용하는 경우 자동적으로 Hikari CP에 대한 의존성 설정이 된다고 한다. DataSource? Connection Pool을 사용하면 미리 정해진 수만큼의 커넥션을 Pool에 만들어두고, 필요할 때마다 이를 꺼내 쓰고 반환한다. 커넥션은 생성 비용이 크기 때문에, 이와 같은 방식으로 연결 비용을 줄여,..