Lock을 활용한 Concurrency Control 기법
Youtube 쉬운 코드 채널의 영상을 보고 정리한 내용입니다.
https://youtu.be/0PScmeO3Fig?si=mP1V2HZCoZni1sSt
Lock의 종류
read-lock (shared lock)
read할 때 사용한다.
다른 트랜잭션이 read 하는 것은 허용한다.
write-lock (exclusive lock)
read/write할 때 사용한다.
다른 트랜잭션이 같은 데이터를 read/write하는 것을 모두 허용하지 않는다.
❗️ write lock이라고 해서, write할 때만 사용되는 것은 아니다! exclusive한 형태라는 점이 중요하다.
lock 호환성
같은 데이터에 대해서, 한 트랜잭션이 어떤 lock을 가지고 있을 때, 다른 트랜잭션도 lock을 동시에 가질 수 있을까?
같은 데이터에 대해서, 한 트랜잭션이 read lock을 가지고 있을 때 다른 트랜잭션에서 동시에 read lock을 가지려고 하는 경우
를 제외하면 모두 불가능하다.
이미 있는 lock이 해제될 때까지 기다려야 한다.
| read-lock | write-lock | |
| read-lock | O | X |
| write-lock | X | X |
Lock 사용 시 이상현상과 2PL
Lock을 사용해도 이상한 현상이 발생할 수 있다.
예를 들면
서로 다른 트랜잭션이 두 데이터 x, y에 대한 작업을 할 때, 각 데이터에 대한 lock 취득 시점, 데이터를 읽는 시점이 다름으로 인해
Nonserializable한 스케줄이 될 수도 있다.
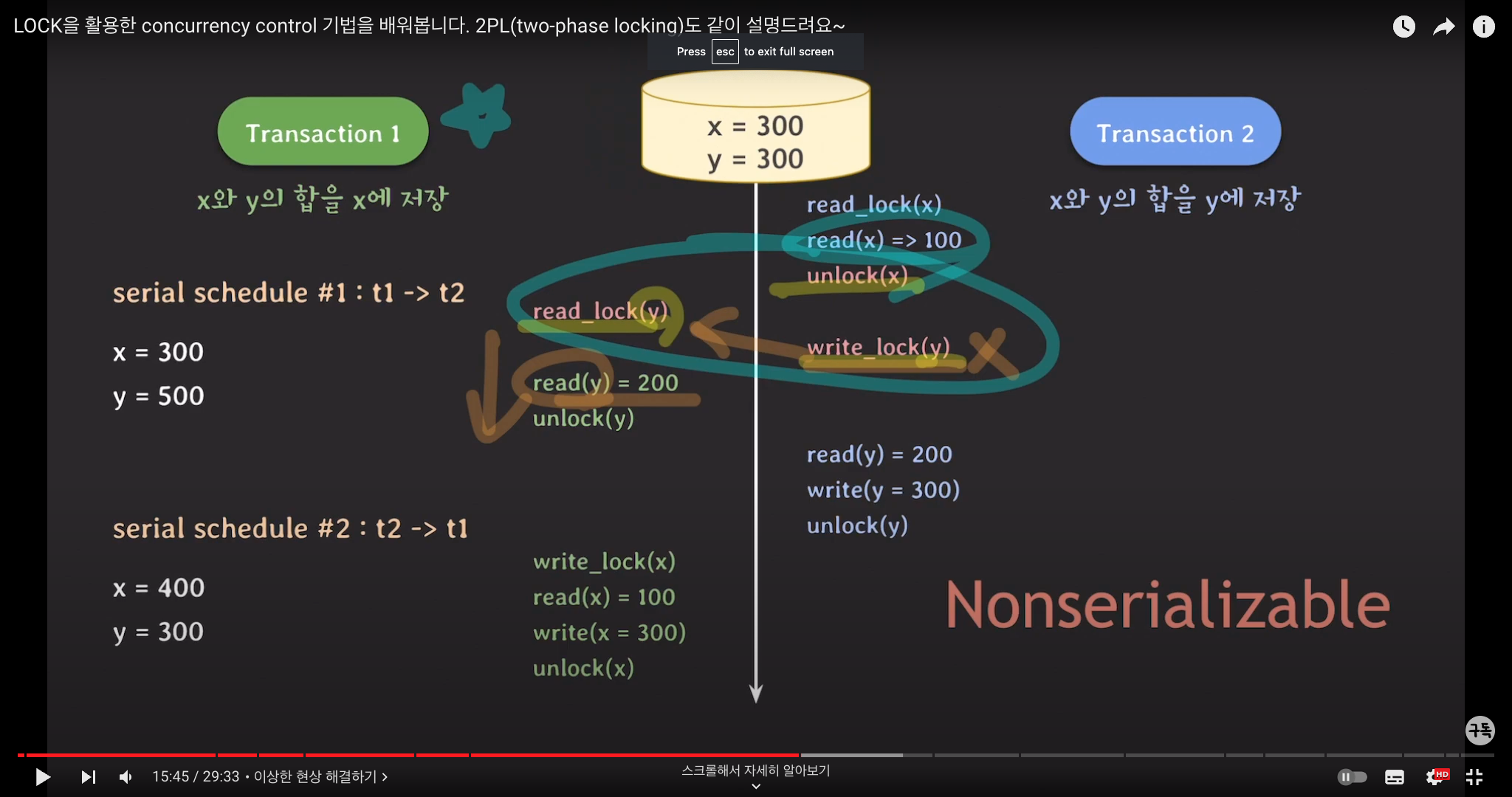
x=100, y=200일 때
T1은 x와 y의 합을 x에 저장 / T2는 x와 y의 합을 y에 저장한다고 하자.
serial schedule이라면, 트랜잭션의 순서에 따라 x, y의 값은 서로 다르다. (300,500 or 400, 300)
하지만 lock을 사용할 때 다음과 같이 동작한다면 nonserializable한 결과가 나온다. (300, 300)
(1) T2가 read_lock(x)에 대한 unlock을 하는 사이에 T1이 read_lock(y)을 획득
(2) T2의 write_lock(y)는 T1의 read_lock(y)이 끝날 때까지 대기 후, 끝나면 y에 대한 쓰기 작업을 진행
-> T2가 먼저 시작했음에도 T1은 T2가 업데이트하기 전의 y의 값을 읽게 된다.
이 현상을 해결하기 위해 2PL을 통해 serializability를 보장한다.
어떻게?
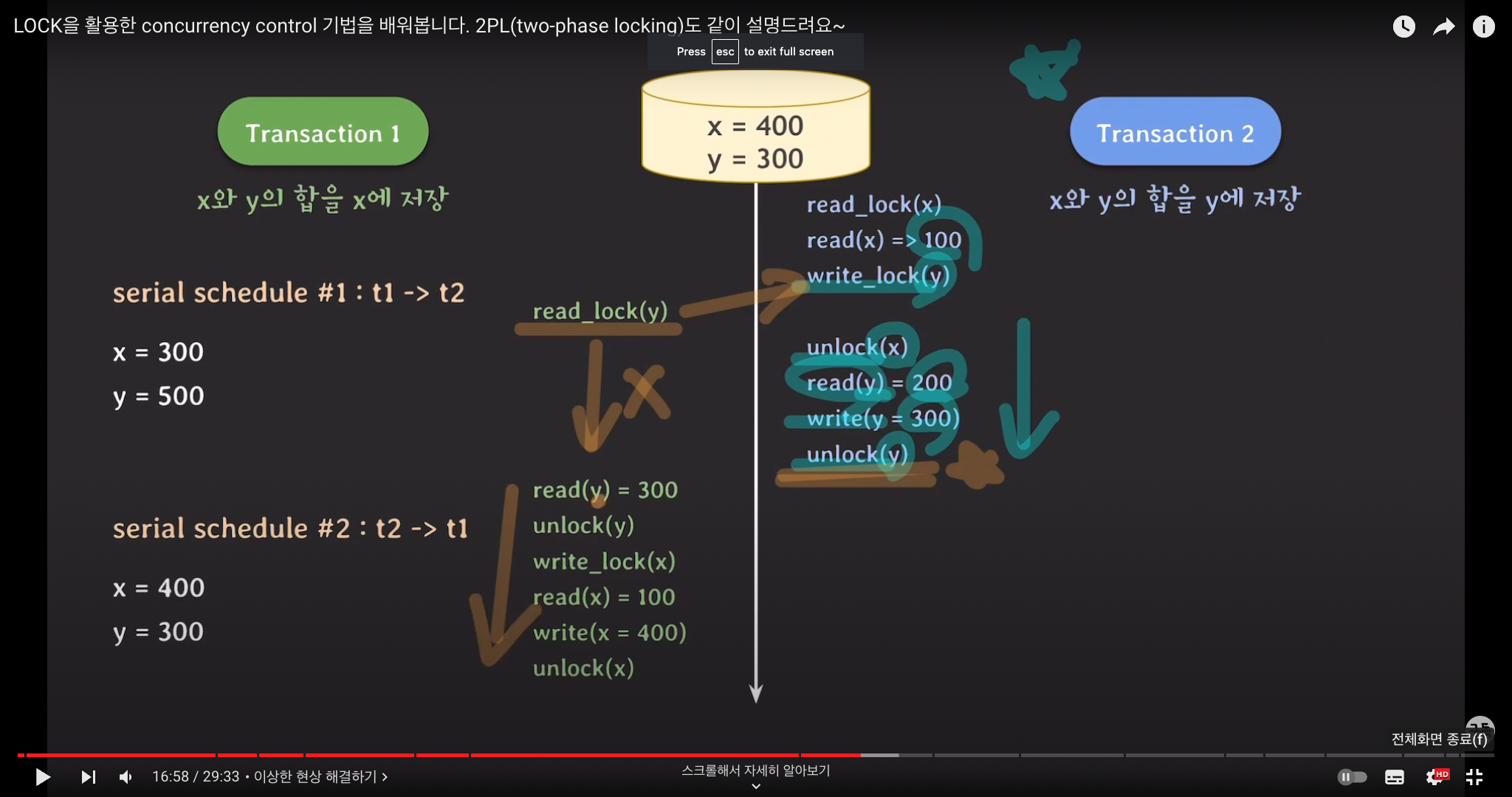
예시로 다시 보자면
T2가 먼저 시작됐다면, T2가 x, y 모두에 대해 먼저 lock을 획득하도록 하자.
T2가 read_lock 으로 x를 읽고, write_lock으로 y를 읽고 쓰는 작업을 먼저 하도록 한다.
이 때 write_lock(y)를 걸어둔 상태이므로 T1의 read_lock은 대기한다.
unlock(x), unlock(y)가 모두 다 된 뒤에야 T1의 읽기, 쓰기 작업이 진행된다.
-> serializable을 보장하게 된다!
반대로 T1를 먼저 시작하는 경우에도, serializable을 보장하기 위해서는
위 이미지에서 unlock(y) <-> write_lock(x)의 위치를 바꿔주어야 한다.
unlock(y)를 하는 사이 T2에서 먼저 x에 대한 lock을 획득할 수 있기 때문이다.
Two-Phase Locking (2PL)
위 해결방법이 2PL 방식인데,
트랜잭션에서 모든 locking operatrion이 최초의 unlock operation 보다 먼저 수행되도록 하는 것이다.
이것을 two-phase locking, 2PL protocol이라고 한다.
취득만 하는 phase와, 반환만 하는 phase로 나누어져 있다는 뜻이다.
다르게 설명하면, 한 번 unlock이 시작되면 그 이후에는 새로운 lock의 취득을 하지 않는다고 볼 수 있다.
Expanding phase (growing phase)
lock을 취득하기만(read_lock, write_lock) 하고 반환하지는 않는 phase
Shrinking phase (conracting phase)
lock을 반환만(unlock) 하고 취득하지는 않는 phase
2PL은 특별한 경우를 제외하면 seralizablity를 보장해준다.
따라서 2PL protocol을 따르도록 RDBMS를 구현하면, 이 때 Concurrency control은 serializability를 보장한다.
(하지만 상황에 따라 데드락이 발생할 수 있다는 점은 알고 있어야 한다.)
2PL의 종류
Conservative 2PL
모든 lock을 취득한 뒤 transaction을 시작한다. (읽기/쓰기 작업 중간에 lock 취득, 반환이 이루어지지 않음)
-> 데드락이 발생하지 않지만, 실용적이진 않다.
Strict 2PL (S2PL)
Strict schedule 을 보장하는 2PL
(어떤 데이터에 대해 write하는 트랜잭션이 있다면, 그 트랜잭션이 끝(커밋/롤백)나기 전까지는 다른 트랜잭션이 그 데이터에 대해 읽거나 쓰지 않는 스케줄)
write-lock을 commit/rollback될 때 반환한다. (read-lock은 스케줄 내에서 반환 가능)
-> recoverability를 보장한다.
Strong Strict 2PL (S2PL)
read-lock 또한 commit/rollback될 때 반환한다.
-> S2PL보다 구현이 쉽다. 대신 lock을 더 오래 쥐고 있어야 한다.
2PL의 약점
lock 호환성을 봤을 때,
read-read를 제외하고는, 항상 한쪽이 block이 되니까 전체 처리량이 좋지 않다.
(그래서 read-write 간의 호환성이라도 더 챙겨보고자 나온 동시성 제어 방식이 MVCC이다.)
답해보기
2PL을 구현하는 이유는?
동시성 제어의 방법으로 Lock을 사용하는 것만으로는 Serializablity를 항상 보장할 수 없다. 따라서 Serializability를 보장하기 위해 2PL을 구현한다. 2PL은 취득과 반환 phase를 나누기 때문에 unlock을 하는 사이 다른 트랜잭션이 먼저 lock을 취득하여 작업을 하는 것과 같이 순서를 보장하는 일을 방지할 수 있다.
2PL 방식으로 구현할 때 데드락의 예시는?
위에서 다뤘던 x+y 를 x, y에 저장하는 예시로 보자면
T1은 read_lock(x)를 가지고 있고 write_lock(y)를 받기를 기다리고 있다.
T2은 read_lock(y)를 가지고 있고 write_lock(x)를 받기를 기다리고 있다.
그러면 둘 다 shrinking phase가 끝나야 반환을 하므로 자신의 lock을 반환하지 않고 서로 기다리는 교착 상태가 발생한다.